

Abstract
Recently introduced Contrastive Language-Image Pre-Training (CLIP) bridges images and text by embedding them into a joint latent space. This opens the door to ample literature that aims to manipulate an input image by providing a textual explanation. However, due to the discrepancy between image and text embeddings in the joint space, using text embeddings as the optimization target often introduces undesired artifacts in the resulting images. Disentanglement, interpretability, and controllability are also hard to guarantee for manipulation. To alleviate these problems, we propose to define corpus subspaces spanned by relevant prompts to capture specific image characteristics. We introduce CLIP projection-augmentation embedding (PAE) as an optimization target to improve the performance of text-guided image manipulation. Our method is a simple and general paradigm that can be easily computed and adapted, and smoothly incorporated into any CLIP-based image manipulation algorithm. To demonstrate the effectiveness of our method, we conduct several theoretical and empirical studies. As a case study, we utilize the method for text-guided semantic face editing. We quantitatively and qualitatively demonstrate that PAE facilitates a more disentangled, interpretable, and controllable image manipulation with state-of-the-art quality and accuracy.
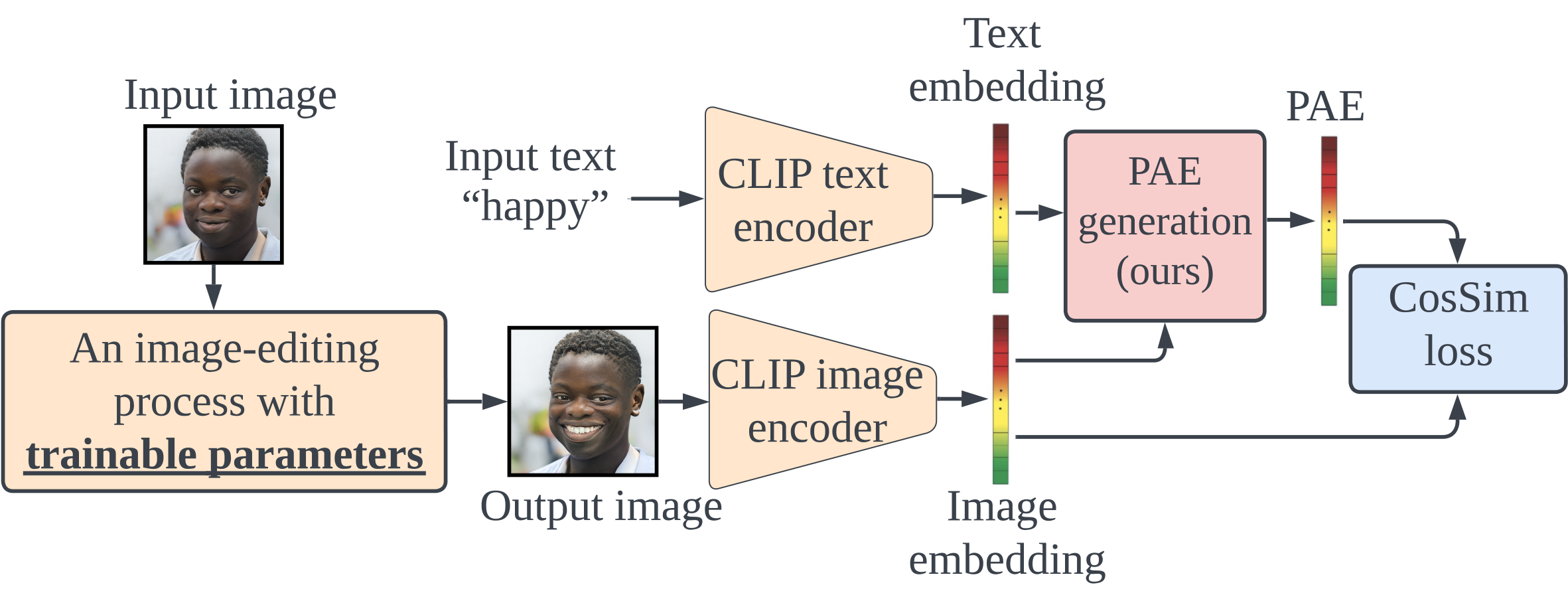
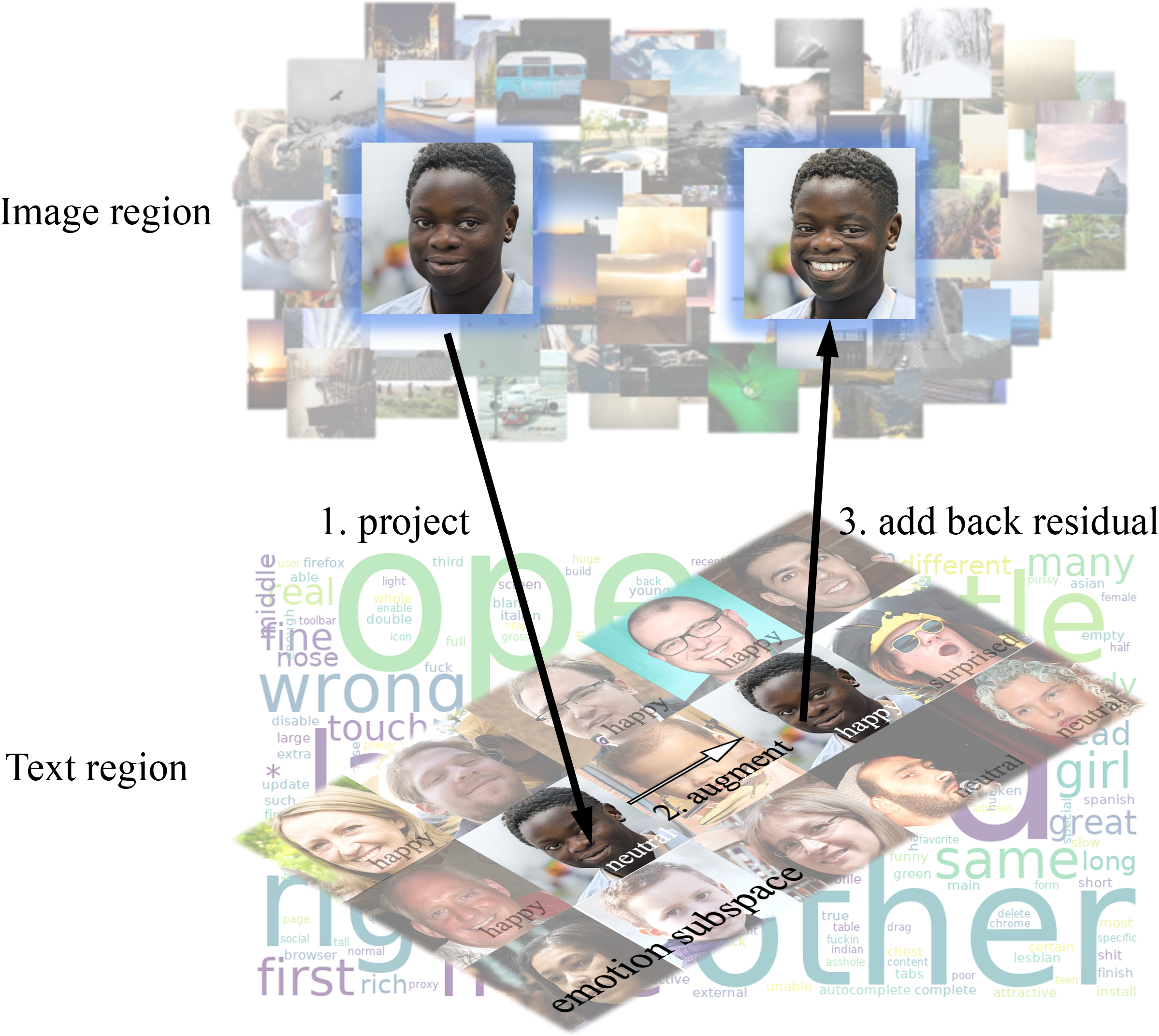
Framework
Further Results

















Citation
@inproceedings{zhou2023clip,
title={CLIP-PAE: Projection-Augmentation Embedding to Extract Relevant Features for a Disentangled, Interpretable and Controllable Text-Guided Face Manipulation},
author={Zhou, Chenliang and Zhong, Fangcheng and Oztireli, Cengiz},
booktitle={Proceedings of ACM SIGGRAPH},
pages={1--9},
year={2023}
}The website template was borrowed from D2NeRF.